Nieman Journalism Lab |
- Getty Images blows the web’s mind by setting 35 million photos free (with conditions, of course)
- Embrace the unbundling: The Boston Globe is betting it’ll be stronger split up than unified
- The New York Times’ football bot is ready for its offseason training regimen
- Interviewing the algorithm: How reporting and reverse engineering could build a beat to understand the code that influences us
| Getty Images blows the web’s mind by setting 35 million photos free (with conditions, of course) Posted: 05 Mar 2014 06:37 PM PST Hey, look, it’s some boiled crawfish: And the great Creole fiddler Cedric Watson: And a stock photo of a professor in a classroom: And Walter Lippmann lecturing in 1952: Those photos are all from the esteemed Getty Images — a place we at Nieman Lab and thousands of other publishers have paid good American money for the use of their photos. And yet I’m not blowing through Harvard’s budget by putting those four photos up there. I’m legally and ethically publishing them all here because Getty has, remarkably, decided to allow 35 million of its images to be used for free for noncommercial purposes. The British Journal of Photography has the story — it’s an attempt to deal with widespread unauthorized posting:
BJP argues that the move “has single-handedly redefined the entire stock photography market,” and while I think that’s a slight overstatement, it’s nonetheless quite significant. Go here and start searching (look for the </> symbol to see which photos are embeddable) to see what you can find. A few thoughts on this big move: The collection is huge, but it has big holes.Not every image you’ll find on Getty can be embedded, and from my initial searches, the share of editorial/news images available seems much smaller than the share of traditional stock photos. Go search for “Obama” and you’ll find a gazillion photos, but I didn’t find too many that could be embedded, like this one: If you need a purely illustrative photo — something to communicate the idea of “hotel room” or “pulled pork sandwich” or whatever — it seems you’re more likely to find something. But if you’re looking for photos from this morning in Crimea, you’re likely to have a harder time. For the online news organizations that already have licensing agreements with Getty, this new embeddability (?) isn’t likely to change the need for them. (Sports photos seemed more frequently embeddable than straight news — again, just from some initial poking around. Here are University of Louisiana point guard Elfrid Payton — you’ll see him in a couple years at the next level! — and New Orleans Saints quarterback Drew Brees.) Getty’s definition of “noncommercial” is bold.
As a publisher (even one without ads!), I like that broader definition — but it’s not the one that most Creative Commons users prefer. (Much, much more about that here and here.) What “noncommercial” means is something Creative Commons has never really been willing to take a clear stand on. (Imagine some extremely hypothetical future day when we put ads on Nieman Lab. Do all the CC photos here become a rights violation or not?) In any event, Getty is clear that its definition of noncommercial is closer to Wired’s than to the typical Creative Commons user’s. Here’s how it puts it in the terms of service:
As Getty told BJP (emphasis mine):
There’s a Trojan horse in the legal language.Getty’s not doing this out of the good of its heart. It recognizes that images on the Internet are treated as de facto public domain by many people on social networks, blogs, and the scummier parts of the content web. It knows it’s highly unlikely to ever get significant money out of any of those people. Even you and I, upstanding Internet citizens, are unlikely to license a photo to tweet it to our followers. So if it can (a) get some people to use an embed instead of stealing while (b) making the experience just clunky enough that paying customers won’t want to use it, Getty could eke out a net win. (More on that second point below.) What does Getty get from the embed? Better branding, for one — the Getty name all over the web. Better sharing, for another — if you click the Twitter or Tumblr buttons under the photos, the link goes to Getty, not to the publisher’s site. But there are two other things Getty gets, according to the terms:
Aha! The data collected could have internal use (measuring what kinds of images are popular enough to invest in more stock photos, for instance). But they could also help with those ads. Imagine a day, five years from now, with Getty photo embeds all over the web, when they flip the switch — ads everywhere. Maybe there’s a photo equivalent of a preroll video ad and you now have to click to view the underlying image. Or a small banner on the bottom 90px of the photo. And imagine your website has used a lot of Getty embeds over the years — enough that Getty can actually sell ads specifically targeting your website, using all that data it’s gathered. Or imagine there are enough Getty embeds that it could sell ads only on photos of Barack Obama, or only photos about Cajun music, or only photos about restaurants in Kansas City. You can start to see the potential there. Think of how many YouTube videos were embedded on other websites before Google ever started putting ads on them. To get to that potential, Getty needs to have its photos everywhere. If it’s already accepted that it won’t make money with these small bloggers and publishers via licensing, why not use them as a Trojan horse? Who knows if it would ever come to that, but it’s a possibility specifically outlined in the terms of service. The embed is kinda crummy.There are at least three significant problems with it from a publisher’s point of view: — The embed, by default, has no way to resize to different dimensions. (Unlike, say, the YouTube embed, which can be quickly resized to whatever size of content well you’d like.) You can change it manually if you’d like by fiddling with the width and height of the embed’s iframe, but that (a) takes math to derive the height from the desired width and (b) isn’t even simple math, because the credit area underneath the photo means that the height/width ratio of the photo isn’t the same as the ratio of the embed. You basically have to change the width and then manually eyeball the height until it looks right. I know, #firstworldpublisherproblems — but it makes the process less friendly. — The embed is not, by default, perfectly responsive. So if your site is meant to adjust responsively from phones up to desktops, your embedded Getty image won’t always adjust with it. There are probably workarounds, as there are for Instagram’s similarly unresponsive image embeds, but again, it’s a pain. — Being restricted to an embed means that the photo can’t travel with the post. For instance, I’d love to use one of the lovely Getty photos in this story as what WordPress calls its “featured image” — meaning the photo that will show up when this story is on our homepage or in a search result or on my author archive page. But I can’t do that with a remote embed — I can only do that with an image that lives on the Nieman Lab server. For Joe Blogger, none of those are likely a deal killer. (It’s even less of a deal for his neighbor, Joe Spam Blogger.) But those guys are probably comfortable just stealing the image directly anyway. I think these technical issues are enough of a roadblock to keep Getty embeds out of nearly any major publisher’s regular workflows. (Also, a technical note: The way the embeds are set up, it’s trivial to resize the iframe to eliminate the Getty Images credit and sharing tools at the bottom. For instance, here’s that same photo of Cedric, only this time resized to cover the credit: Looks a lot like I paid for that photo now, doesn’t it? (I’m no lawyer, but I don’t even see how this violates the terms of service around embeds.) I’m not sure this is a “redefinition” of the stock photo market.There’s no doubt that this will further increase negative pricing pressure on the stock photo market. But that negative pricing pressure has been around for years. Ever since 2000, when iStockphoto burst onto the scene and radically undercut the existing competition, which was charging many multiples of iStock’s price. In 2006, iStockphoto, the great undercutter of pro photography business models, was bought by… (In other words, these guys understand disruption in the photo business.) This move requires uptake, but the right kind of uptake. Ideally, it would generate new value among the web scofflaws while not harming Getty’s business with pro publishers. I’m not sure these embeds hit that balance. The workflows are too ungainly for the people who currently have contracts with Getty, true, but they’re also not quite easy enough to be a good substitute for people who don’t mind stealing. My wager is that, as transformational as this announcement might seem to be, Getty’s embeds won’t be pockmarking the web. But no matter how it turns out, give Getty a lot of credit for being willing to take a highly unorthodox stance. It’s an effort very much worth watching. |
| Embrace the unbundling: The Boston Globe is betting it’ll be stronger split up than unified Posted: 05 Mar 2014 12:52 PM PST The model for the 20th-century American newspaper was to be all things to all people, in one amalgamated package. One daily bundle of newsprint could give you baseball box scores, reports of intrigue in Moscow, gardening tips, an investigation into city hall, and Calvin and Hobbes. The Boston Globe is betting that the model of the 21st-century American newspaper won’t be a single digital product — it’ll be a lot of them. Since 2011, the Globe has been perhaps the best known proponent of what’s been known as the two-site strategy: a paid site that includes the newspaper’s top journalism (BostonGlobe.com) and a free site that aims to be more realtime, quick-hit, and webby (Boston.com). It’s a strategy that hasn’t been without problems — ask your average Bostonian to describe the difference between the two sites and you might get a confused look — but the Globe’s plan for the future is to separate the sites even more, not to bring them back together. And they’ll be spawning still more digital offshoots along the way — each free-standing, even battling its own siblings where appropriate. “We think there is plenty of room for both of these sites,” Globe editor Brian McGrory told me. “Our intention is they compete like crazy with each other.” Of the numerous changes the Globe’s announced this week, perhaps the most important is the replacement of BostonGlobe.com’s hard paywall with a meter — up to 10 free stories a month. The tradeoff is that Boston.com will no longer publish any content generated by the Globe’s staff: not just newspaper stories but also staff blogs, chats, and more. With the exception of video, which the sites will still share, everything else moves over to BostonGlobe.com. The hope is that’ll make the distinction between the two clearer, and that the meter will mean that the webbier parts of Globe-produced content will still have a chance to reach a non-paying audience. For Boston.com, the separation is physical, too: Its staffers are moving out of the Globe newsroom into their own space, essentially making the two sites roommates. (Albeit roommates who’ll be moving soon; new owner John Henry has said he plans to sell the company’s Morrissey Boulevard property.) A Boston.com redesign, in the works for several years now, is finally approaching launch, on mobile by the end of March and on desktop in April. McGrory told me the new strategy should help the sites become more distinctive, which in turn should drive an increase in audience. “We’re hoping obviously that it boosts traffic significantly,” he said. “But let’s be clear though: The paywall worked. It did exactly what we wanted it to do.” The company increased its digital subscribers from 28,000 in 2012 to 47,000 in 2013 to “nearly 60,000″ today. McGrory said a metered paywall will help grow the audience by giving potential subscribers a sample of the Globe’s work. “Essentially we’re doubling down the bet on our own journalism,” McGrory said. And the two-site strategy is just the beginning. On Monday, the company launched BetaBoston.com, a site focused on the local tech and biotech industries. Last fall it launched BDCwire, an arts and entertainment site aimed at younger readers. And this spring, the Globe plans to debut a site covering Catholicism anchored by reporter John Allen. “You’ve seen a lot of organizations over the past few months focus on niche verticals. That’s something we believe strongly in,” said David Skok, the Globe’s new digital advisor (and, full disclosure, a recent Nieman Fellow). Michael Morisy, editor of BetaBoston (and a former Lab contributor), said the site has the potential to amplify the work the Globe has already been doing on innovation, from startups in Kendall Square to biotech companies. (It’s a space with some competitors already in place, like BostInno and Xconomy.) Operating independent of the Globe (though it’ll include contributions from Globe staffers) means BetaBoston can build an audience of people who might not regularly read the Globe, Morisy said. “We aren’t just covering startup funding or apps: We’re covering things more broadly,” Morisy said. “Internally, I refer to our domain as how innovation is enhancing greater Boston and how Boston innovation is changing the world.” Similarly, McGrory said the Catholic site has a strong potential readership both in the Boston area and beyond. “Here in Boston, we know we have a pretty Catholic state and a pretty Catholic region. We think there is a reasonably good fit there,” he said. Expect more to come. While he wouldn’t say what the next Globe digital franchises might be, McGrory said he thinks the three key sectors in Boston are technology, health care, and education. If BetaBoston is successful, those other two could be the next targets. “My every hope is to use that for a template for what we do in the other concentrations next,” McGrory said. In the broader sense, the Globe wants to build its fortunes off a collection of distinct audiences rather than one monolithic one: dedicated news hounds going to BostonGlobe.com, information grazers at Boston.com, younger readers and music lovers at BDCwire, and the tech-inclined at BetaBoston. It’s part of continuing change at the Globe under Henry, which has also included new subscription enticements in print. But the digital moves are also a course correction on the company’s digital strategy. In the two years since the Globe divided its digital presence, BostonGlobe.com has allowed the company to grow a digital subscription business from scratch — an important new source of revenue in an uncertain environment for online advertising. But the brand confusion between the two sites has been a persistent problem and the relaunch of Boston.com has been a work-in-progress for years.
The fate of Boston.com is something that is also clearly on the mind of Henry. In his profile of the publisher last month, Jason Schwartz of Boston Magazine wrote: “The vision for the new Boston.com is to be, as Henry puts it, ‘a phone-first website’ and totally independent of the Globe — something like a mixture of the Huffington Post with BuzzFeed.”
When I spoke to Skok on Tuesday, he said he’s planning to apply some of the ideas of disruptive innovation in his new role at the Globe. Specifically, Skok said disruptive innovation emphasizes making sure that the priorities and resources at the heart of a company are aligned with experimentation. Launching independent sites, and creating clearer lines between Boston.com and BostonGlobe.com, will go a long way towards helping that, Skok said. McGrory sees the Globe’s future in similar terms: “It says we’re going to be as innovative as we need to be in digital formats, that we’re willing to experiment and willing to try new things,” he said. Photo by Scott LaPierre used under a Creative Commons license. |
| The New York Times’ football bot is ready for its offseason training regimen Posted: 05 Mar 2014 10:55 AM PST NFL teams spend the offseason reflecting on the past season and preparing for the next one. So like any good playcaller, the team at The New York Times’ 4th Down Bot is spending the months between the Super Bowl and the start of the 2014 preseason examining what it’s learned and how it can improve for the coming season.
On his personal GitHub today, Kevin Quealy, a graphics editor at the Times, writes about how the project was developed and outlined some of the bot’s successes (more than 10,000 Twitter followers!) and areas where it could be improved (a slow response time). The bot launched in time for Week 13 of the NFL season (in the midst of my Lions’ annual late season collapse, when the bot was a welcome tool to further question now-fired coach Jim Schwartz’s competence). Quealy said the bot probably should’ve launched sooner — a non-football kind of MVP — and he outlines a few other issues he might try to address in training camp:
In his post, Quealy wrote that they’re “hoping to introduce a cousin or two this summer, too.” In a followup email, Quealy told me he’s looking to apply some of the successful aspects of the 4th Down Bot to other fields — possibly baseball or politics. “But it’s not like I have a super secret project on my desktop that is already [4th Down Bot's] next of kin,” he wrote. “Plus, we’re hoping to add features and build on our audience with 4th Down Bot, which is not an insignificant amount of work.” |
| Posted: 05 Mar 2014 09:39 AM PST Often, when there’s talk about algorithms and journalism, the focus is on how to use algorithms to help publishers share content better and make more money. There’s the unending debate, for example, over Facebook’s News Feed algorithm and whose content they’re giving preference to. Or there are people like Chris Wiggins, recently interviewed by Fast Company, who uses his decade long career as a biology researcher and data scientist to advance the mission of The New York Times, from outside the newsroom. But Nick Diakopoulos, a Tow Fellow at Columbia, wants to expand what journalists think about when they think about algorithms.
Diakopoulos doesn’t mean using algorithms to visualize data, though. He wants reporters to learn how to report on algorithms — to investigate them, to critique them — whether by interacting with the technology itself or by talking to the people who design them. Ultimately, writes Diakopoulos in his new white paper, “Algorithmic Accountability Reporting: On the Investigation of Black Boxes,” he wants algorithms to become a beat:
Investigating algorithms is Diakopoulos’s main focus at Tow. Over the summer, he did some research into Google’s auto-complete algorithm, ultimately publishing his findings at Slate. Diakopoulos then became interested in how other journalists were getting to the core questions of algorithm building. Specifically, he wanted to know what processes they were using to figure out what goes into an algorithm, and what is supposed to come out. After looking at examples of investigations into algorithms from ProPublica, The Wall Street Journal, The Atlantic, The Daily Beast and more, Diakopoulos wrote up his observations for The Atlantic. The Tow white paper, published last month, is an expansion of those thoughts and inspired a panel at the NICAR conference held last week in Baltimore, where Diakopoulos shared the stage with Frank Pasquale, The Wall Street Journal’s Jeremy Singer-Vine, and The New York Times’ Chase Davis. “I started developing the theory a little bit more and thinking about: What is it about algorithms that’s uncomfortable for us?” Diakopoulos told me. “Algorithmic power is about autonomous decision making. What are the atomic units of decisions that algorithms make?” It’s inherently challenging for people to be critical of the decisions that machines make. “There’s a general tendency for people to be trusting of technology,” says Diakopoulos. “It’s called automation bias. People tend to trust technology rather than not trust technology.” Automation bias is what causes us to follow wrong directions from a GPS, even if the route is familiar. It’s also, some say, what tragically caused Air France Flight 447 to crash into the Atlantic in 2009. In the same way, Diakopoulos argues, we believe that Match.com’s algorithms want us to find true love, that Yelp wants to find us the best restaurants, and that Netflix wants to show us the most entertaining movies. Diakopoulos argues that it’s a journalist’s responsibility to determine whether that’s true or if it’s just what those companies want us to believe. (Remember: Media companies use algorithms too, which means “some of the same issues with transparency arise” there as well.) “Because [algorithms] are products of human development, there may be things that we can learn about them by talking to the people who built them,” says Diakopoulos. In the paper, he writes that “talking to a system's designers can uncover useful information: design decisions, descriptions of the objectives, constraints, and business rules embedded in the system, major changes that have happened over time, as well as implementation details that might be relevant.” But more often than not, interviewing engineers is not an option — even government algorithms are protected by a FOIA trade secret exception that shields third-party source code. There is at least one known instance of source code being successfully accessed via FOIA: But ultimately, Davis said, reporters shouldn’t expect to get much information out of the government. “Reporting on these things and getting information out of institutions is similarly black-box. These things are protected trade secrets. FOIAing source code, if it was put together by a government contractor, or even maybe the government itself? Good luck. Probably not going to happen.” At NICAR, Pasquale told journalists to pay attention as laws about accessing technological information develop. “I would recommend that everyone in this audience, to the extent that journalists can be advocates, that we closely follow the workshops on data brokering and algorithm decision making that the FTC is putting on,” he said. If you can’t talk to the people that wrote the algorithm, what next? “When corporations or governments are not legally or otherwise incentivized to disclose information about their algorithms, we might consider a different, more adversarial approach,” Diakopoulos writes.
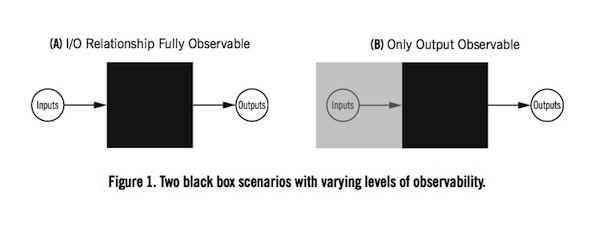
That approach is reverse engineering, which basically means putting things into an algorithm, observing what comes out, and using that information to make some guesses about what happened in between — the zone of the black box. It’s an idea supported by a basic principle of engineering: Taking something apart is a good way of learning how it works.
When The Wall Street Journal and Singer-Vine wanted to find out whether or not online vendors like Staples were selling items for different prices based on who the shopper was, they also used reverse engineering. The paper built proxy servers and developed user profiles to create “painstakingly simulated inputs” which they compared to the price outputs. What they found was that stores seemed to be varying their prices based on where customers were located geographically. “If you think about a cell in your body, a biologist is reverse-engineering that cell to understand how it works. They’re poking and prodding it, and seeing how it responds, and trying to correlate those responses to come up with some theory for how that cell works,” Diakopoulos says. Citing Paul Rosenbloom’s book On Computing: The Fourth Great Scientific Domain, Diakopoulos argues that some of our algorithmic systems have become so large, they’re more usefully thought of as resembling organisms rather than machines. “The only way to really understand them is by applying the same techniques that we would apply to nature: We study them with a scientific method. We poke and prod them and see how they respond.” Singer-Vine spoke to the same issue at NICAR. As algorithmic systems grow and grow, finding a language to explain what you’ve learned without using misleading metaphors or implying causation where it doesn’t exist is only going to get more complex. “To translate your findings is only going to get harder,” he says. “If an algorithm is so complex that nobody can explain why one thing happened because of another, maybe that’s a story in and of itself.” Of course, there are challenges and risks to using reverse engineering. Ultimately, while it can sketch a story, it can’t tell you exactly why or how engineers wrote an algorithm. “Just because you found a correlation between two variables in reverse engineering, doesn’t mean there was some programmer who wrote that algorithm who decided that it should be that way. It might have been an accident. There may have been some complexity in the algorithm that was unforeseen. You can’t make the inference that this was done on purpose,” says Diakopoulos. Nick Seaver, who studies algorithmic cultural phenomena at UC Irvine, says that while Diakopoulos’s examples of journalistic reverse engineering are intriguing, he’s ultimately more of a pessimist regarding reverse engineering’s potential as a reporting tool. In an email, Seaver writes:
At NICAR, Pasquale brought up another example, Nathan Newman’s 2011 investigation into potential racial implications for the algorithm that determines the personalization of Google ads. While Newman’s findings were interesting, Pasquale says, “Google says you can’t understand their methodology based on personalization.” Their full rejection of his claims were:
But Diakopoulos sees a future where the tactics of reverse engineering and the tools of reporting are blended into a unified technique for investigating algorithms. “You see how far you can get — see if you can find something surprising in terms of how that algorithm is working. Then, you turn around and try to leverage that into an interview of some kind. At that point, the corporation has an incentive to come out and talk to you about it,” he says. “If you can combine that with observation of the system through reverse engineering, then I think through that synthesis you get a deeper understanding of the overall system.” As journalists charge after this potential new trend in data journalism, however, it’s worthwhile to remember this note from Diakopoulos on the consequences of revealing too much about the algorithms we rely on. He writes: “Gaming and manipulation are real issues that can undermine the efficacy of a system. Goodhart's law, named after the banker Charles Goodhart who originated it, reminds us that once people come to know and focus on a particular metric it becomes ineffective: ‘When a measure becomes a target, it ceases to be a good measure.’” During the NICAR panel, Singer-Vine raised the same issue, pointing out that making the mechanics of algorithms publicly available also makes them more “gameable.” (Ask all the SEO consultants for whom understanding Google’s search algorithms is the holy grail.) But Pasquale pushed back on this concern, arguing, “Maybe we should try to expose as much as possible, so that the people involved will build more robust classifiers.” Diakopoulos’ plans to move forward with algorithm investigations are primarily academic. Although the paper concludes it’s too soon to consider how best to integrate reverse engineering into j-school curricula, Diakopoulos says it’s a major interest area. “I think if we taught a joint course between journalism and computer science, we would learn a lot in the process,” he says. Primarily, he’s interested in finding more examples of journalists using reverse engineering in their work — not that he has any shortage of his own ideas. Given the opportunity, Diakopoulos says he’d be interested in investigating surge pricing algorithms at companies like Uber, exploring dating site algorithms, looking for bias in selection of immigrants for deportation, and more. He’s also had conversations with Columbia’s The New York World about collaborating on an investigation of New York municipal algorithms. For journalists who want to be thinking more critically — and finding more stories — about the machines we rely on, Diakopoulos offered some advice on newsworthiness. “Does the algorithm break the expectations we have?” he asked. “Does it break some social norm which makes us uncomfortable?” Visualization of a Toledo 65 algorithm by Juan Manuel de J. used under a Creative Commons license. |







| You are subscribed to email updates from Nieman Journalism Lab To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |